

之前在项目开发中发现每个人编写的SQL格式都有点不一样,比如缩进/关键字大小写不一样,当时就在想有没有类似Python的Black库那样可以格式化Python代码来保持一样代码风格?
那就是今天要介绍的sqlparse库了。
简介
sqlparse是一个用来解析SQL查询语句的轻量级Python库。它并不执行SQL查询操作,而是专注于解析和格式化SQL语句。它可以帮助开发者处理SQL代码的缩进、格式化以及拆分复杂查询,甚至支持对查询结构的分析。
- 格式化:对凌乱的
SQL语句进行格式化,输出可读性强的代码。 - 解析:将
SQL语句解析为结构化的token流,便于进一步的操作。 SQL分析:支持对SQL语句中的结构进行深入分析,识别出关键字、表名、列名、函数等组件。
安装
在开始使用sqlparse之前,我们需要先安装该库。你可以通过Python的包管理工具pip进行安装:
pip install sqlparse安装完成后,便可以在项目中导入并使用sqlparse了。
基础用法
sqlparse的核心功能主要包括两部分:格式化和解析。
格式化
SQL语句的格式化是sqlparse最基本的功能之一。通过简单的函数调用,开发者可以将一行SQL语句自动格式化为多行、缩进合理的代码,从而提高可读性。
假设有一个复杂的SQL语句,它在一行中很难阅读:
import sqlparse
sql = """
select a.id, b.key, c.name, d.addr, f.mid from a left join b on a.id = b.id left join c on a.name = c.name left join d on d.key = b.key left join (select e.addr, f.mid from e join f on e.mid = f.mid) t on t.addr = d.addr WHERE b.key IS NOT NULL and c.name != '' order by a.id desc limit 100
"""
formatted_sql = sqlparse.format(sql, reindent=True, keyword_case='upper')
print(formatted_sql)运行这段代码后,你将得到一个格式化后的SQL语句:
SELECT a.id,
b.key,
c.name,
d.addr,
f.mid
FROM a
LEFT JOIN b ON a.id = b.id
LEFT JOIN c ON a.name = c.name
LEFT JOIN d ON d.key = b.key
LEFT JOIN
(SELECT e.addr,
f.mid
FROM e
JOIN f ON e.mid = f.mid) t ON t.addr = d.addr
WHERE b.key IS NOT NULL
AND c.name != ''
ORDER BY a.id DESC
LIMIT 100sqlparse.format()函数提供了许多可选参数,使开发者能够自定义格式化的行为:
keyword_case:用于控制关键字的大小写。可选值包括:'upper':将关键字转换为大写。'lower':将关键字转换为小写。
reindent:启用后将自动重新缩进SQL代码,默认值为False。indent_width:指定缩进的宽度,默认为2。strip_comments:启用后将删除SQL语句中的所有注释,默认值为False。
所以,我们可以启用多个选项来生成更加个性化的格式, 以美化我们平常写出来的复杂的SQL语句。
解析
sqlparse不仅可以格式化SQL,还可以对SQL进行解析。它可以将SQL语句拆分成多个token,便于开发者对SQL的结构进行深入分析。
基本解析
我们可以使用sqlparse.parse()函数来解析SQL语句,并生成一个Statement对象列表,其中每个Statement对象表示一条SQL查询语句。
import sqlparse
sql = """
select id, name, age from users limit 10;
select id, name from coms limit 10;
"""
parsed = sqlparse.parse(sql)
for index, stmt in enumerate(parsed):
print(index, ":", stmt.value.strip())输出:
0 : select id, name, age from users limit 10;
1 : select id, name from coms limit 10;这将输出被解析的SQL语句的结构。在这里,parsed是一个包含Statement对象的列表,开发者可以对每个Statement对象进行进一步操作。
Token 的概念
sqlparse使用Token的概念来表示SQL语句中的每一个组成部分,包括关键字、表名、操作符等。通过sqlparse,我们可以轻松提取这些信息。下面是一个简单的示例:
import sqlparse
sql = """select id, name, age from users limit 10;"""
parsed = sqlparse.parse(sql)
for stmt in parsed:
for token in stmt.tokens:
print(token.ttype, token.value)输出:
Token.Keyword.DML select
Token.Text.Whitespace
None id, name, age
Token.Text.Whitespace
Token.Keyword from
Token.Text.Whitespace
None users
Token.Text.Whitespace
Token.Keyword limit
Token.Text.Whitespace
Token.Literal.Number.Integer 10
Token.Punctuation ;这段代码将逐个输出每个token的类型和值。ttype是token的类型,如关键字、运算符等,而value是token的实际值。
Token类型分类
sqlparse库中的Token类型被分类为多个类别,如:
Keyword:SQL中的关键字,如SELECT、FROM等。Identifier:表名、列名等标识符。Literal:字面值常量,如数字和字符串。Operator:SQL中的操作符,如=、>、<等。开发者可以根据需求对这些不同类型的token进行分类或过滤。
SQL分析
借助sqlparse的解析能力,我们可以进一步对SQL结构进行分析。这对复杂的SQL查询尤为有用,尤其是当开发者需要从查询中提取表名、列名或其他组件时。
提取表名
通过sqlparse,我们可以轻松提取出SQL查询语句中使用的表名。以下是一个简单的示例:
import sqlparse
from sqlparse.sql import Identifier
from sqlparse.tokens import Keyword
def extract_tables(sql):
parsed = sqlparse.parse(sql)
stmt = parsed[0]
tables = []
for token in stmt.tokens:
if isinstance(token, Identifier):
tables.append(token.get_real_name())
elif token.ttype is Keyword and token.value.upper() == 'FROM':
pass
return tables
sql = "SELECT id, name FROM users u JOIN orders o ON u.id = o.user_id"
tables = extract_tables(sql)
print(tables)该函数会解析SQL并返回查询中涉及到的所有表名。在这个例子中,输出为:
['users', 'orders']提取列名
类似地,我们也可以提取SQL查询中的列名。这个操作非常适合用于需要对SQL查询进行静态分析的场景。
import sqlparse
from sqlparse.sql import IdentifierList
def extract_columns(sql):
parsed = sqlparse.parse(sql)
stmt = parsed[0]
columns = []
for token in stmt.tokens:
if isinstance(token, IdentifierList):
for identifier in token.get_identifiers():
columns.append(identifier.get_real_name())
return columns
sql = "SELECT id, name, age FROM users"
columns = extract_columns(sql)
print(columns)输出结果将为:
['id', 'name', 'age']高级用法
在前面的基础功能介绍之外,sqlparse还提供了一些高级特性,帮助开发者处理更加复杂的SQL查询。
SQL语句拆分
sqlparse支持对多条SQL语句进行拆分,这对需要批量处理或分析多个SQL查询时非常有用。以下示例展示了如何使用sqlparse.split()函数来拆分多条SQL语句:
import sqlparse
sql = "SELECT * FROM users; INSERT INTO users(id, name) VALUES (1, 'Alice');"
statements = sqlparse.split(sql)
for statement in statements:
print(statement)输出:
SELECT * FROM users;
INSERT INTO users(id, name) VALUES (1, 'Alice');sqlparse.split()函数会根据SQL中的分号(;)将SQL语句拆分成多个独立的语句。
定制化解析
除了内置的Token类型和解析逻辑,sqlparse还允许你定制解析过程。通过对Statement对象的深入分析,开发者可以编写自定义规则来处理复杂的SQL查询。
过滤器
sqlparse中的过滤器机制可以让开发者在解析过程中动态操作Token流。你可以通过编写过滤器来操作SQL结构中的各个部分,例如关键字、标识符或表达式。
例如,我们可以编写一个简单的过滤器,将所有SQL关键字转换为小写(这个其实可以用sqlparse.format()自身也可以实现):
import sqlparse
class LowerKeywordFilter:
def process(self, stmt):
def process_token(token):
if token.is_group:
for sub_token in token.tokens:
process_token(sub_token)
elif token.is_keyword:
token.value = token.value.lower()
return token
for token in stmt.tokens:
process_token(token)
return stmt
sql = "SELECT ID, NAME FROM USERS WHERE AGE > 30;"
parsed = sqlparse.parse(sql)[0]
lower_keyword_filter = LowerKeywordFilter()
processed_stmt = lower_keyword_filter.process(parsed)
print(processed_stmt)输出结果:
select ID, NAME from USERS where AGE > 30;通过过滤器,开发者可以对SQL语句中的任何元素进行操作。
SQL格式定制化
除了基础的SQL格式化功能外,sqlparse还允许开发者根据需求进一步定制输出格式。
比如。忽略部分元素。sqlparse允许你在格式化时忽略某些元素。例如,如果SQL语句中包含注释,但你希望忽略这些注释,可以使用strip_comments=True选项:
import sqlparse
sql = "SELECT ID, NAME -- this is a comment\nFROM USERS"
formatted_sql = sqlparse.format(sql, reindent=True, strip_comments=True)
print(formatted_sql)输出结果:
SELECT ID,
NAME
FROM USERS注释被自动移除,这对在生产环境中处理分析大量SQL查询时可能非常有用。
SQL代码审查
sqlparse不仅仅是可以用于分析SQL代码,还可以用于审查SQL,提升SQL安全性和规范性。
比如在项目过程中硬性规定创建一个表设计不能超过5个普通索引,那我们可以拉出数据库的建表语句或者保留在项目中DDL(Data Definition Language,数据定义语言) 文件, 通过sqlparse检查脚本检测哪些已存在的或准备提交创建的表不合规(当然这只是其中一种思路,方法不只一种)
import sqlparse
def check_indexes_count(ddl_statement):
index_count = 0
parsed = sqlparse.parse(ddl_statement)
for statement in parsed:
tokens = statement.flatten()
for token in tokens:
if token.ttype == sqlparse.tokens.Keyword and token.value.upper() == 'INDEX':
index_count += 1
return index_count > 5
ddl = """CREATE TABLE my_table (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
address INT,
INDEX idx_name (name),
INDEX idx_age_name (age, name),
INDEX idx_another (id),
INDEX idx_more (age),
INDEX idx_extra (name),
INDEX idx_address (address)
);"""
if check_indexes_count(ddl):
print(f"该DDL语句中有超过5个索引。")
else:
print(f"该DDL语句中没有超过5个索引。")输出:
该DDL语句中有超过5个索引甚至我们在单元测试的时候,审查级别还可以下沉到DML(Data Manipulation Language, 数据操作语言) 即将操作的层面来进行SQL分析审查,比如检查改查询语句where条件里是否用了非索引字段进行查询,是否有SQL注入风险等
应用场景
由于sqlparse具备灵活的SQL解析与格式化功能,它在多个开发场景中扮演着重要角色。以下是sqlparse的一些典型应用场景:
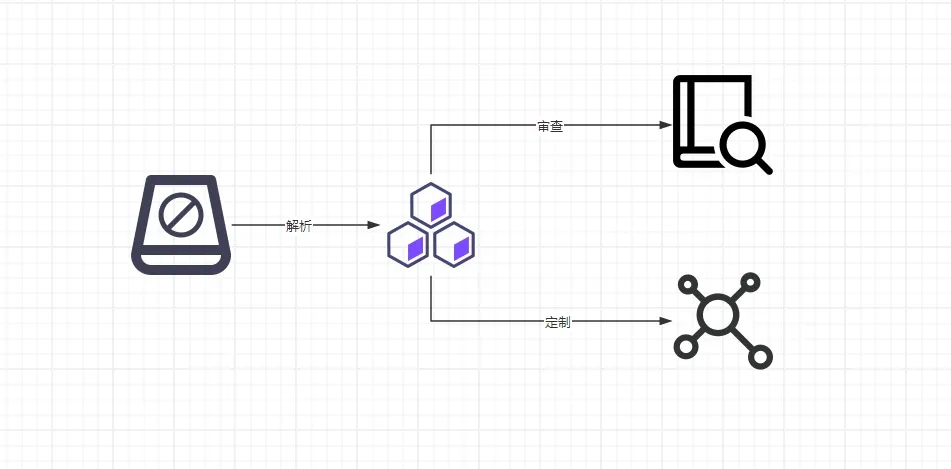
- 在开发过程中,
SQL查询语句常常会变得复杂且难以阅读。sqlparse可以自动对SQL进行格式化,确保查询语句结构清晰、缩进合理。这在代码审查中尤为重要,有助于提高SQL代码的可读性和维护性。 - 使用
sqlparse的解析功能,开发者可以自动化地分析SQL查询,提取表名、列名、关键字、索引等信息。这种静态分析能力可以帮助检测潜在的SQL性能问题,并为查询优化提供数据支持。 - 在数据库系统中,
SQL查询日志记录了用户的所有查询操作。sqlparse可以用于解析和分析这些日志,帮助开发者追踪查询行为、检测潜在的安全问题或生成审计报告。 - 在数据迁移和管理过程中,
sqlparse可以解析复杂的SQL脚本,自动调整查询结构或生成新的SQL语句。这对于大规模数据库迁移或自动化SQL脚本生成非常有用。
总结
sqlparse不仅是一个简单的SQL格式化工具,它还提供了强大的SQL解析功能。
通过使用sqlparse,开发者可以简化复杂的SQL查询操作,提升SQL代码的可读性,并为静态分析审查与查询优化提供坚实的基础。
如果你觉得本文对您有一点点帮助的话,希望能得到您的一点点支持,也欢迎在评论区说出您自己的见解。