

在 Python 编程中,print函数是最基础但却非常重要的工具之一。它不仅用于输出信息到控制台,还可以用于调试和展示程序的运行状态。
print 函数在python3里已经从python2的关键字升级为了函数,这让它有了更丰富的用法和玩法,今天我们将深入探讨print函数的各种用法和参数设置。
常用玩法
最简单的
最简单的 print 函数调用只需要一个参数,通常是我们的第一个python程序的内容
print("Hello, world!")这段代码将输出 Hello, world! 到控制台。
Hello, world!多个参数
print 函数可以接受多个参数,并将它们以空格分隔的形式输出:
print("Hello", "world", 2024)输出结果为:
Hello world 2024自定义分隔符
通过sep参数,可以自定义多个参数之间的分隔符(默认情况下sep参数指定为空格符)。例如,指定使用逗号和空格作为分隔符:
print("Hello", "world", 2024, sep=", ")输出结果为:
Hello, world, 2024自定义结束符
默认情况下,print 函数输出内容后会自动添加一个换行符。可以通过 end 参数自定义结束符,例如使用空格代替换行符:
print("Hello, world", end=" ")
print("Welcome to Python!")输出结果为:
Hello, world Welcome to Python!输出到文件
print 函数的 file 参数允许我们将输出重定向到文件而不是控制台。例如,将内容写入一个文本文件:
with open("output.txt", "w") as file:
print("Hello, world!", file=file)这段代码会在当前目录下创建一个名为 output.txt 的文件,并在其中写入 Hello, world!
flush 参数
flush 参数控制输出缓冲区的刷新。如果设置为 True,print 函数会立即将内容输出到目标设备,而不是等待缓冲区满或程序结束时再输出:
import time
print("Loading", end="", flush=True)
for i in range(5):
time.sleep(1)
print(".", end="", flush=True)输出结果为:
Loading.....上面代码每隔一秒钟会打印一个点,是不是很像某个下载或者进度加载过程?
高级用法
格式化输出
使用 f-string(格式化字符串)来更灵活地格式化输出内容,这样输出的内容更加连贯(而不是像空格有割离感):
name = "Jeff"
age = 25
print(f"Name: {name}, Age: {age}")输出结果为:
Name: Jeff, Age: 25另外,Python3.8以上的版本甚至可以这样打印
name = "Jeff"
age = 25
print(f"{name=}, {age=}")输出为:
name='Jeff', age=25多行输出
可以使用三重引号(””” 或 ”’)来输出多行字符串:
print("""
Line 1
Line 2
Line 3
""")输出结果为:
Line 1
Line 2
Line 3花活玩法
带颜色字符串
使用 ANSI 转义序列可以在支持这些序列的终端中输出带颜色的文本。以下是一些常见的 ANSI 转义序列:
前景色:
- 黑色:
\033[30m - 红色:
\033[31m - 绿色:
\033[32m - 黄色:
\033[33m - 蓝色:
\033[34m - 紫色:
\033[35m - 青色:
\033[36m - 白色:
\033[37m
背景色: - 黑色:
\033[40m - 红色:
\033[41m - 绿色:
\033[42m - 黄色:
\033[43m - 蓝色:
\033[44m - 紫色:
\033[45m - 青色:
\033[46m - 白色:
\033[47m
重置颜色: \033[0m
例如:
print("\033[32m这是绿文本\033[0m")
print("\033[33m这是黄色文本\033[0m")
print("\033[31m\033[47m这是红色白底文本\033[0m")输出:
循环加载
上面已经有一个loading加载的例子了,但是有些时候,我们重复在某一行进行循环加载,尤其是模拟网络下载时(比如像npm install某些库时的命令行动态效果)。
因为涉及到同行循环,所以会用上退格符 \b,来回退覆盖已经输出的字符串。
import time
print("Loading", end="", flush=True)
for _ in range(5):
for _ in range(3):
time.sleep(1)
print(".", end="", flush=True)
time.sleep(1)
print("\b\b\b \b\b\b", end="", flush=True)其实还有其他特殊字符(如\t、\r等)可以和print进行联动
打印形状
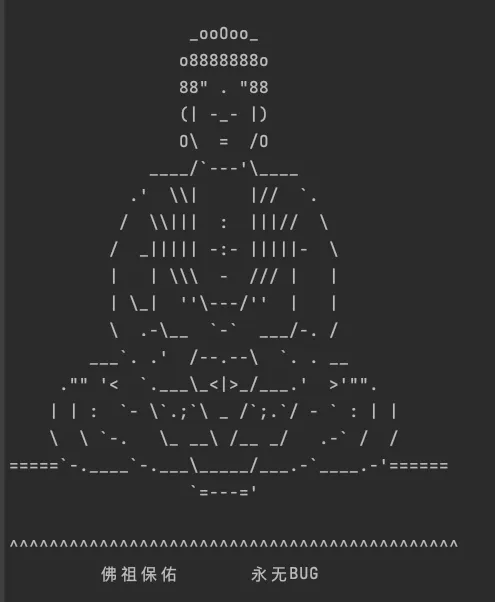
打印爱心
print('\n'.join([''.join([('*' if ((x * 0.04) ** 2 + (y * 0.1) ** 2 - 1) ** 3 - (x * 0.04) ** 2 * (y * 0.1) ** 3 <= 0 else ' ') for x in range(-30, 30)]) for y in range(15, -15, -1)]))效果图:

“佛祖保佑,永无BUG”,这个打印可以用在程序启动的时候,有buff加成,非常玄学。
注意,这里用的是raw stingr字符串,主要是避免里面的\符号被转义了。
print("""
_ooOoo_
o8888888o
88" . "88
(| -_- |)
O\ = /O
____/`---'\____
.' \\| |// `.
/ \\||| : |||// \\
/ _||||| -:- |||||- \\
| | \\\ - /// | |
| \_| ''\---/'' | |
\ .-\__ `-` ___/-. /
___`. .' /--.--\ `. . __
."" '< `.___\_<|>_/___.' >'"".
| | : `- \`.;`\ _ /`;.`/ - ` : | |
\ \ `-. \_ __\ /__ _/ .-` / /
=====`-.____`-.___\_____/___.-`____.-'======
`=---='
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
佛祖保佑 永无BUG
""")输出:
打印logo
以打印“X秘书”为例
print("""
X X X X X X
X X X X X X XXXXXXXX X
X X X X X X X
X XXXXXXX X X X X XXXXXXXXXXXX
X X X X X X X X X
X X X X X X x X xXX
X X X X X X XXXXXX X
"""
)输出:
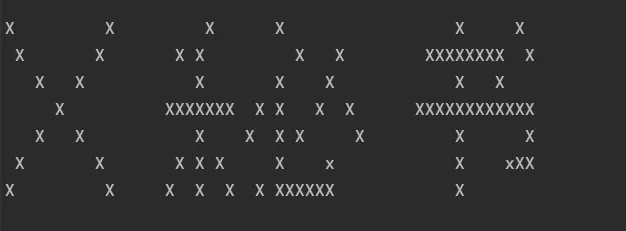
结论print 函数是 Python 中最基本但却功能强大的工具之一。通过了解和掌握 print 的各种参数和用法,可以更高效地调试和展示程序的运行结果。
如果你还发现print有其他玩法,欢迎讨论交流