写出“高大上”、优雅的Python代码是一种艺术,其中代码的优雅是围绕着简洁性、可读性和可维护性展开。接下来说说python开发中常见的一些技巧和技法,可以帮助你写出优雅的 Python 代码。
使用“_”下划线代替一些无用变量
下划线“_”在python代码中和普通的“abc”一样也可以做为变量名存在,而且它表示的是上一个表达式执行结果,所以在遇到一些元祖/列表进行参数解包的情况时,有些参数可能会解包后用不上,为了不引入具体的变量名,可以把参数解包给下划线“_”变量,让代码看起来无需关注这个无用的变量名,比如
time_range = ("2023-05-01", "2024-05-01")
_, end = time_range # 这里表示第一个参数后面用不上,只需要end参数
print(end) # 使用end参数
2024-05-01
列表推导式
列表推导式生成的是一个list对象,一个简单的列表推导式是这样子的:
squares = [x ** 2 for x in range(10)]
但其实列表推导式基本上在数据格式转化场景会用的比较多,比如原数据格式里的items每一项dict的key是“id”,但返回时希望是“item_id”且每一项dict只有一个“item_id”属性,那么用列表推导式就很容易实现转化
items = [{"id": 1}, {"id": 2}, {"id": 3}]
ret_items = [{"item_id": it["id"]} for it in items]
print(ret_items)
[{'item_id': 1}, {'item_id': 2}, {'item_id': 3}]
你甚至可以在里面进行一些条件过滤判断之类
ret_items = [{"item_id": it["id"]} for it in items if it["id"] % 2 == 0]
字典推导式
与列表推导式类似,字典推导式生成的是一个dict对象,字典推导式最常用的是字典的key、value值进行兑换,但请注意key、value值是要一一对应的,不能存在多对一情况:
k2v = {"a": 1, "b": 2, "c": 3}
v2k = {v: k for k, v in k2v.items()}
print(v2k)
{1: 'a', 2: 'b', 3: 'c'}
max/min代替if大小判断
if a > b:
ret_value = a
else:
ret_value = b
改成
ret_value = max(a, b)
defaultdict提前生成默认格式
有时候在生成一些数据时,需要保持一定的格式,比如有个这样的场景,某个dict如果新增一个key时,你希望这个key对应value是个可以支持append数据的list。正常情况下,你得先确保这个key对应的value是一个list,然后才可以append,类似:
d = {}
if "key1" not in d:
d["key1"] = []
d["key1"].append("kv1")
d["key1"].append("kv2")
而你可以使用defaultdict来避免每当加入一个新的key时都需要初始化其value为list, 比如这样:
from collections import defaultdict
d = defaultdict(list)
d["key1"].append("kv1")
d["key1"].append("kv2")
defaultdict(list)表示创建一个 defaultdict 字典,它的默认值是一个空列表 (list)。defaultdict 是 Python 标准库 collections 模块中的一个类,它提供了字典的功能,并允许你为字典中的键设置一个默认值。
在普通字典中,如果你尝试访问一个不存在的键,通常会引发 KeyError 异常;然而,在 defaultdict 中,如果你尝试访问一个不存在的键,它会自动为该键创建一个默认值。通过在 defaultdict 中设置默认值为 list,任何在字典中不存在的键会自动被初始化为一个空列表。
defaultdict还可以指定其他工厂函数(或类型),比如list、set、int或者某个类,其作用就是任何在字典中不存在的键会自动被初始化为一个空对象或类的实例
函数/方法代码尽可能不要太长
设计函数/方法时,让其只完成一个具体的任务,这样可以提高代码的可读性和可维护性。最好一个函数/方法的代码最好控制在50行以内,如果太长,那么它设计上很有可能已经违背了单一职责原则了
代码缩进块不要太多
应该不会有人喜欢看这种多层级缩进的代码吧?
for b in a:
if b[0]:
for c in b[1]:
if c[0]:
for d in c[1]:
if d[0]:
print(d[1])
缩进太多会导致可读性很差,很有可能是数据结构设计不合理或者是函数/方法没有遵循单一原则导致,一般建议是超过5个缩进就应该拆一拆代码了
使用类型注解
使用 Python 3 的类型注解可以提高代码的可读性,并有助于静态类型检查。
def concatenate_strings(s1: str, s2: str) -> str:
return s1 + s2
多个平级if…else…改成字典映射
某些简单的多if…else…值判断情况下可以考虑转化成字典映射,将条件和操作映射到字典中,然后通过条件直接查找操作。这种方式适用于明确的条件和操作对,比如:
def perform_action(action):
actions = {
'a': do_action_a,
'b': do_action_b,
'c': do_action_c,
}
func = actions.get(action, default_action)
func()
当然映射的value也可以是函数
def handle_a():
# 处理条件为 'a' 的情况
pass
def handle_b():
# 处理条件为 'b' 的情况
pass
def handle_c():
# 处理条件为 'c' 的情况
pass
def handle_default():
# 处理默认情况
pass
def handle_condition(condition):
handlers = {
'a': handle_a,
'b': handle_b,
'c': handle_c,
}
handler = handlers.get(condition, handle_default)
handler()
添加测试用例代码
编写测试用例可以确保代码的正确性,尤其是在代码重构时提供信心,也能防止其他人改错你的代码。
代码注释
虽然好的代码就是文档注释,但是对于有些带坑或者历史遗留的问题代码最好还是要注释一下,不然过了一阵子就真的可能只有上帝才知道这段代码是什么意思了
使用一些辅助工具实现PEP 8代码风格
这里比较推荐三个python的三个静态代码检查工具(第三方库):flake8、isort、black
flake8 是一个 Python 代码检查工具,用于检测代码中的潜在问题,包括编码风格、潜在错误和规范问题。它结合了三个工具:PyFlakes、pycodestyle 和 McCabe,以提供全面的代码分析,让你代码看起来很整洁统一,比如它能帮找出:
- py文件最后一行是否留有空行
- 函数块上下是否留有两行空行
- ……
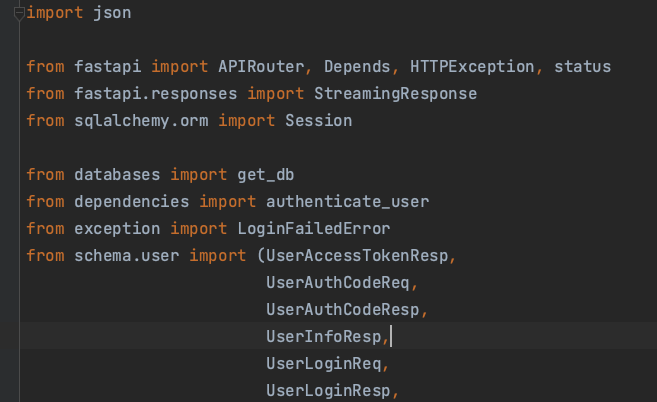
isort 是一个 Python 工具,用于自动对 Python 脚本中的导入语句进行排序和组织。它可以根据代码中的导入依赖关系自动调整导入顺序,以提高代码的可读性和一致性,效果如下:
import json
import time
from fastapi import APIRouter
from fastapi import Depends
from fastapi import HTTPException
from fastapi import status
from fastapi.responses import StreamingResponse
from sqlalchemy.orm import Session
from databases import get_db
from dependencies import authenticate_user
black 是一个 Python 代码格式化工具。它可以自动将代码格式化为符合 PEP 8 编码规范的样式。black 被设计成”无辩论”的代码格式化工具,只要运行它,它就会重新格式化代码,使其保持一致。
总结
以上就是一些平常可能会用上技法技巧,如果你都用上了,相信你的代码一定会比别人写的更优雅好看